
五部门关于开展2024年江南网页版登录入口官网下载 下乡活动的通知
首页 > 江南app官方版下载
特斯拉拒绝激光雷达,何来的底气?
来源:江南网页版登录入口官网下载
网
时间:2021-06-26 12:07:15
热度:
特斯拉拒绝激光雷达,何来的底气?本文来源:智车科技/ 导读 /其实在谈到这个事情之前,我们再来回顾一下2020年11月份的时候小鹏汽车何小鹏和特斯拉的马斯克激光雷达的路线是否适合L
本文来源:智车科技
/ 导读 /
其实在谈到这个事情之前,我们再来回顾一下2020年11月份的时候小鹏汽车何小鹏和特斯拉的马斯克激光雷达的路线是否适合L3及以上的自动驾驶路线,在网上引起非常激烈的讨论。
在自动驾驶日上马斯克曾强调Lidar is lame,激光雷达是个瘸子, 他认为激光雷达捕获的点云数据是信息量缺失的,虽然有空间信息,但是没有颜色,没有图案,静止状态下无法区分动/静态物体,也无法分辨特征类型。
自动驾驶日上也曾有记者向马斯克提问:激光雷达是否会在自动驾驶某个难以突破的 99.999% 节点成为一个更好的冗余方案?
然而马斯克直接给了一个更绝情的回复,他的观点:激光雷达是fool's errand,是无用功,而同行里以激光雷达为主要感知手段的也是doomed,注定失败。
他的理由非常简单,因为激光雷达对于自动驾驶应用而言是昂贵且没有必要的,马斯克甚至用阑尾来形容激光雷达,一个阑尾就够糟了,还带一堆,简直荒谬。
总结一下,马斯克或者说特斯拉对于激光雷达的观点可以概括为:
机械式的激光雷达丑的掉渣,价格又非常昂贵,相对于视觉方案没有不可完全的替代性
小鹏汽车确实是公认的特斯拉追随者。除去主打智能化,尤其是辅助驾驶的战略上类似特斯拉,小鹏汽车的产品端也有很多的细节和逻辑可以看到特斯拉的影子。
特斯拉的路既然被证明是走得通的,那么有选择地跟着走其实也是一种稳妥的战略。
然而在激光雷达问题上,小鹏汽车却随大流了。
在这次上海车展上,小鹏P5直接给出20W电动汽车的王炸。P5竟然提供激光雷达,大疆Livox为小鹏P5提供的这套激光雷达,这个是大疆的首款车规级激光雷达HAP,HAP利用Livox自研的“超帧率”激光雷达探测技术,可以做到针对低反射率为10%的物体(如黑色汽车)探测距离150米,横向视场角120度,角分辨率0.16度X0.2度,点云密度等效于144线激光雷达。此外,大疆在激光雷达布局上也有不少创新,可以跟双目摄像头集成,也可以跟左右后视镜集成。
采访中关于搭载激光雷达的考虑,何小鹏的回复如下:
「我们跟传统做第四代自动辅助驾驶的或者他们叫无人驾驶的公司不太一样,他们是用激光雷达为核心画激光雷达的高精地图, 我们不一样,我们是用视觉为核心,以视觉高精地图为核心。因为我们觉得从趋势来看,全球所有的路、交通灯、法规都是以人的眼睛等等角度来看一个世界去开车的,我们认为这是最有效率、最接近真人且最便宜的,且又能够加上激光雷达组合能够把安全做好的事情。说实话,在最开始几年里面我们会把安全的因数放在非常非常非常重的角度, 宁愿我硬件冗余、宁愿软件冗余,也要把安全做好。」
小鹏汽车仍然以视觉为核心感知手段,激光雷达的作用是作为安全冗余。对于小鹏汽车以及多数企业而言,将激光雷达和相机数据做融合感知是非常有意义的事情。

ADAS进程中传感器的成长过程
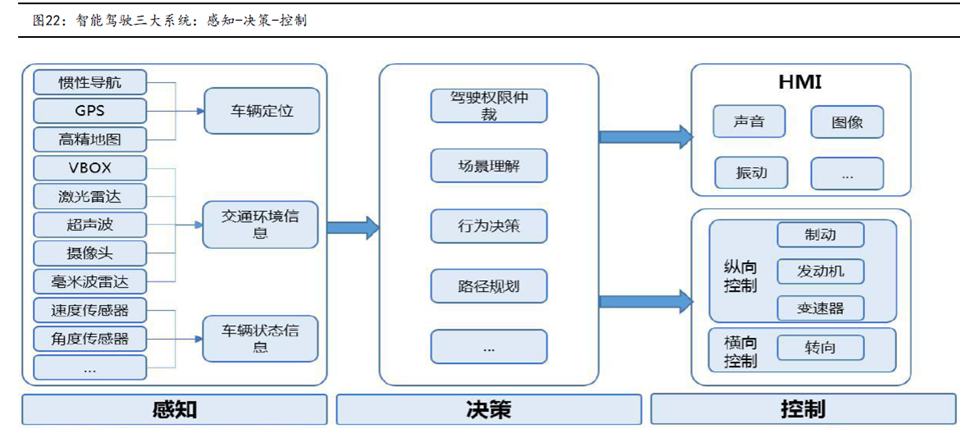
还是经典的自动驾驶三大架构,感知、决策、执行层。
感知层:主要由激光雷达、 摄像头、高精度地图、IMU/GPS等部分构成,主要负责搜集车身周边信息;
决策层:以感知信息数据为基础,根高算力的计中心获取经过优化的驾驶决策;
执行层:基于决策层给出的驾驶决策,对制动系统、发机转向等控下达指令,负责驾驶执行;
自动驾驶的基础原理与流程在于:首先由感知层的传感器获取与构建精确路况信息(包含物体建模与车辆定位等),再由感知层输出的信息进行决策规划,向执行端发出指令,
最后由执行端对车辆行为进行实际操控。
从L2 到L3 级别自动驾驶的升级,意味着从辅助驾驶到(有限度)无人驾驶的跃进,对于高精度建模、海量实时运算的要求指数级增长,背后的技术难度随之大幅增长,其中关键环节就在于前端感知,即如何感知与构建路况的完整模型。
要理解这些系统,我们可以回想一下平时咱们是怎么开车的:
第一是眼睛的环境感知方面:车道的位置,前方是否有车辆行驶,红灯和绿灯的交换,这些工作都是由超广角、快速对焦、无级调光圈、双目即时测距、损伤自修复的超高性能仿生摄像头——眼睛来完成的。
更为重要的是,此仿生摄像头自带极强的人工智能处理器,自动完成图像处理(例如剔除毛细血管的遮挡、插帧补全盲点像素等)、对象识别(例如红绿灯、车道)、轨迹预测(前方的车辆即将转弯)等功能之后,将信息上报给“上层意识”。
另外是大脑的行为决策:通过环境感知的信息来判断车辆需要执行的控制策略,例如前方车辆停止,需要紧急刹车等。还要提到的是,像“今天走不走高速”的路径规划也属于广义的决策功能。
还有事手脚的控制执行:在收到大脑的决策指令后,驾驶员的神经、四肢,以油门刹车与方向盘作为人车交互的两大媒介,与整个汽车系统一起承担车辆控制的功能。所以目前来看,AD AS系统中最难、最关键的还是感知系统。
感知其实就是替代人类的眼睛和耳朵,那驾驶环境中无非最重要的两个因素,一个是这个是什么东西,第二个是这个东西的外形大小,移动速度是多少,我们在开车的时候根据看到的物体及判断这个物体移动的速度来做对应的判断。
感知系统这么多传感器,我们首先来看看类似人眼睛的摄像头。

视觉处理技术
拍到什么东西,这个还不容易,现在手机图像识别技术都不能用炉火纯青来形容,可以是登峰造极阶段了,难道在车载上面还有很大的难度?图像识别已经在购物、场景识别,图片识别等各方面有应用了。我的华为手机里面的照片,直接就可以识别出来这个是什么东西,价格是多少,在哪里可以购买。
我们先以最简单的人脸购物识别来看这项技术流程。
人脸识别支付技术是采用通过在设备上安装高清摄像头,消费者在付款的时候,摄像头对人脸进行智能采集,提取人脸面部特征,可以对人脸的静态面貌、动态面貌进行不同角度的采集,从而达到识别身份的目的,具有较高的安全性和便利性。
人脸支付识别系统流程
1、人脸识别系统通过摄像机对人脸的数据进行采集,可以智能采集各种人脸,对人脸进行采集时候可以对人脸进行跟踪,确保采集到的是有效的人脸数据。

2、在对人脸的图形进行采集完成后,系统可以根据采集到的图像,进行处理,由于采集到的人脸受到光线、表情以及角度的影响,所以要进行处理,通过光线补偿、几何校正等技术,对人脸进行修复。
3、人脸识别后进行匹配。在采集到人脸后,系统会自动从数据库里面开始检索,检索到匹配度最高的人脸信息,通过设置一个匹配度的值,如果对比的结果超过或者约等于这个设置的值,就对人脸信息进行输出,所以总体来说,匹配的依据就是根据人脸的相似值,值越高,那么匹配度就越精准。
这里可以看到这里的图像识别和我们常见的指纹识别原理基本上类似,只是指纹识别的数据库是保存在本地(一个指纹锁支持的指纹数量也不会超过100个,一个公司的指纹打卡机器也就是1W个左右),首先进行人脸特征数据的加密采集存储,当需要购买东西的时候,进行人脸的特征点的采集,然后进行数据库的相似度的对比,最终输出对比结果。
这里几个比较关键的点是,由于购物的人脸的数据量特别大,所以需要进行云端的数据存储,这里的特征点采集的多少,直接影响到数据运算速度的快慢,而且本身采集的时候就需要灯光,图像都非常好的情况下才能采集保存,同时在支付的时候也需要比较好的灯光和图像环境,有的时候还需要眨眼睛等活体检测。
可以看到这里使用的环境都是比较良好的,采集的图像亮度比较好,距离比较近,像素识别率也高,需要识别的物体也不多(主要是人脸)而且仅仅是做数据库的相似度比较,对于算力的要求也是特别高,能够快速比对出来具体的信息。
当然如果是把所有物体的特征值全部采集都放到云端,足够强的算力,通过5G传输能够把结果快速反馈回来给到车机端,理论上这条道路也能走通,但是云端的数据库要非常非常多的物体的特征值(要把世界上的绝大部分的物体特征值都存储,万千世界,这个库要非常大),库越大,对比的工作量就越大,所需要的时间就越长,而且5G传输返回结果也有延迟,在信号不稳定的情况下,就没有办法及时获得结果。从最初的图像到结果的输出,一般要求在20ms之内,这个目前的算法下基本上做不到,所以只能走单机智能的道路,其实有点类似语音识别,基本上都是本地的算法进行识别输出,深度学习的推理端都放在本地,训练放在云端。

特斯拉为什么有勇气对激光雷达say no
视觉方案通过摄像头,致力于解决“拍到的是什么”问题。从工作原理来看,视觉方案以摄像头作为主要传感器,通过收集外界反射的光线从而进一步呈现出外界环境画面,即我们所熟悉的摄像头功能,再进行后续图像分割、物体分类、目标跟踪、世界模型、多传感器融合、在线标定、视觉SLAM、ISP 等一系列步骤进行匹配与深度学习,其核心环节在于物体识别与匹配,或者运用AI 自监督学习来达到感知分析物体的目的,需要解决的是“我拍到的东西是什么”的问题。
要解释特斯拉的视觉系统怎么能做到这么牛掰,就得先看看现在各大机构诟病的视觉方案有哪些局限性,针对这些局限性,特斯拉是怎么解决的。

1、精度问题 & 视野问题
测距精度低且依赖项较多,算法固定的情况下只能通过增大焦距或双目镜头间的基线距来提高精度,但焦距增加导致视场角变小,基线距增加导致能看到的最近距离变远。
双目系统最多能覆盖目标方向60度的视野,而激光雷达基本上都是360度。
其实这个问题在单个摄像头的时候确实是一个问题,角度变大,那么距离必然变小,如果测距要远,可视的FOV角度又变小,影响到周围环境物体的判断,是一个鱼和熊掌不可兼得的问题,俗话说的好,小朋友才做选择题,像特斯拉这样的彪汉是距离远&角度大 两个问题全都要解决。
特斯拉就是一个钢铁直男,既不选择单目,也不选择双目,前视摄像头直接就选择三目摄像头。
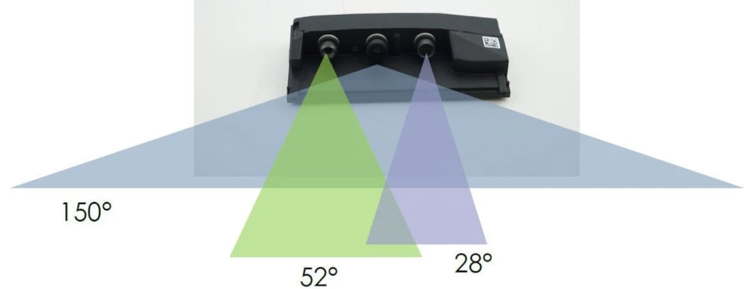
这个三目摄像头安装于挡风玻璃后,由3个组成:前视宽视野、主视野、窄视野摄像头。
宽视野:大角度鱼眼镜头能够拍摄到交通信号灯、行驶路径上的障碍物和距离较近的物体,非常适用于城市街道、低速缓行的交通场景。最大监测距离 60 米。
主视野:覆盖大部分交通场景,最大监测距离 150 米。
窄视野:能够清晰地拍摄到远距离物体,适用于高速行驶的交通场景。最大监测距离250米。
通过这个三目摄像头,钢铁直男把鱼和熊掌不可兼得的问题解决了,既有宽FOV角度的摄像头,像十字路路况比较复杂的路况就需要宽角度,高速路上需要有远距离的摄像头,一起解决了这个问题。
2、双目测距精度与标定有关且强相关,但是装在车上机械结构稳定性差,面临着隔段时间就得标定的问题,同时识别道路和交通标示比较困难。
其实这里就是测量距离的稳定性问题,视觉方案距离检测难度大。自动驾驶的路径规划需要3D 的道路信息和3D 的障碍物,而基于摄像头收集到的仅是2D 数据,因而要求分析2D 图像的每个像素,将其还原成真实的3D 场景,其背后需要先进的图像处理算法以及高算力硬件,并且可能误差较大。
双目视觉是通过对两幅图像视差的计算,直接对前方景物(图像所拍摄到的范围)进行距离测量,而无需判断前方出现的是什么类型的障碍物。所以对于任何类型的障碍物,都能根据距离信息的变化,进行必要的预警或制动。双目视觉的原理与人眼类似,利用双目三角测距的原理,能非常精准的测量物体的距离。
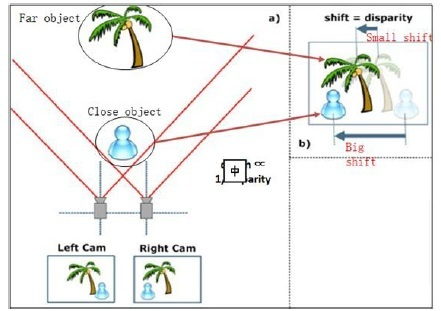
特斯拉利用三目摄像头可以很好的解决单目摄像头测距精准度不高的问题,而且固定的机械位置选择合理,这部分就能解决稳定性的问题,省去隔段时间就需要标定的问题,当然也可以通过软件算法进行远程标定,这个就是考验每家厂家的算法功力的时候了。
再来解决识别道路和交通标示的问题,其实这个是通过摄像头安装的角度问题来解决这个问题。

采用三组相机同步成像,GPS授时授地理位置,不同安装倾角,不同焦距
短焦与长焦相机分距离识别信号灯,限速牌,道路标示等交通信号
这样做的好处是既能提取近处高视角的交通标示,也能使远处交通标示成像足够大,在20年4月份的时候特斯拉就在美国推出了FSD方案,解决了自动识别交通信号灯和停车标志,技术上是比较容易解决的问题。
通过这个三目摄像头,可以做很多ADAS的功能。
像自动紧急刹车(AEB)、车道偏离预警(LDW)、车道保持(LKA)、行人警示(PCW)、自动泊车(AP)、交通标志识别(TSR)、交通信号灯识别(TLR)等都需要建立在图像识别的基础上,进而实现车道线障碍物以及行人检测的ADAS功能,都可以通过这个三目摄像头来实现。
2、软件算法难度的问题
视觉方案重在分类,但样本有限度限制了视觉识别正确性,而优化样本对于AI 学习能力、样本数据量要求极高。
视觉的测距原理是先通过图像匹配进行目标识别,识别行人、物体、车型等。再通过目标在图像中的大小去估算目标距离。由于L3 级及以上自动驾驶需要机器应对较为复杂的路况,要求车辆对于道路状况有精准识别能力,而视觉技术需要解决的是“摄像头拍到的是什么物体”的问题,因而对于神经网络训练集要求很高。
对于训练的方法,一种为通过机器视觉,人为设定好识别样本,通过收集到的数据直接与样本匹配来识别的方式,但是能否成功辨别物体高度依赖样本的训练,样本未覆盖的物体将难以辨别;首先需要建立并不断维护一个庞大的样本特征数据库,保证这个数据库包含待识别目标的全部特征数据。比如在一些特殊地区,为了专门检测大型动物,必须先行建立大型动物的数据库;而对于另外某些区域存在一些非常规车型,也要先将这些车型的特征数据加入到数据库中。如果缺乏识别目标的特征,就会导致系统无法对车型、物体、障碍物进行识别,从而也就无法准确估算这些目标的距离,导致ADAS 系统的漏报。
另一种为AI 学习,能够通过自学习的方式摆脱样本限制,但是对于算法与算力要求很高,并且其学习过程是个“黑盒子”,输出结果的过程未知,因而难以人为调试与纠错。
其实这个算法难度问题才是视觉方案中最难解决的问题,没有金刚转不揽瓷器活,太多的视觉方案厂家到这里就基本上就放弃了。我们看看钢铁直男特斯拉怎么解决这个问题的。
特斯拉的视觉方案具有很高的算法与算力复杂度。特斯拉曾公布过自己数据流自动化计划的终极目标“OPERATION VACATION”,从数据收集、训练、评估、算力平台到“影子模式”形成数据采集与学习循环。

数据收集:通过8 个摄像头对车体周围进行无死角图像采集;
数据训练:使用PyTorch 进行网络训练,特斯拉的网络训练包含48 个不同的神经网络,能输出1000 个不同的预测张量。其背后训练量巨大,特斯拉已耗费70000 GPU 小时进行深度学习模型训练;
背后算力支持:特斯拉自研打造了FSD 芯片,具有单片144TOPS 的高算力值。另外,特斯拉规划创造Dojo 超级计算机,可在云端对大量视频进行无监督学习训练,目前距离开发出来的进度非常值得期待;
影子模式:特斯拉通过独创“影子模式”来降低样本训练成本、提高识别准确度,即特斯拉持续收集外部环境与驾驶者的行为,并与自身策略对比,如果驾驶者实际操作与自身判断有出入,当下数据就会上传至特斯拉云端,并对算法进行修正训练。
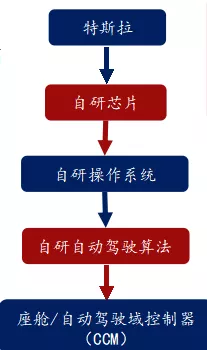
从数据采集,本地芯片硬件处理、图像的软件算法处理、再到后台的超级计算机进行训练,这个需要一系列的技术支持,最好从芯片、操作系统、算法、控制器都是自研,这样才能把芯片的性能发挥最佳,从Mobileye的黑盒子开发模式,直接就让车厂彻底放弃了这条纯视觉处理的道路,不投入几千亿估计门都摸不着方向,所以目前只有特斯拉这样的理工男对于激光雷达有勇气say no,主要是特斯拉可以软硬件一体化调试,加上有海量的跑路视觉数据,云端的Dojo超级计算机大数据算法,这些都让其他厂商无法复制特斯拉的模式。
参考资料:
1、小鹏「吃了几碗凉粉」,激光雷达是对是错?
2、车载传感器技术和产业链梳理,自动驾驶加速渗透
- End -


-
松下出售全部特斯拉股票,套现36亿美元2021-06-26
-
特斯拉在挪威、瑞典开放超充网络,中国市场是否有机会呢?2021-06-25
-
花近80万买新车却没法上牌,特斯拉被判“退一赔一”!2021-06-25
-
小鹏汽车第四款SUV将于明年推出,搭载高级自动驾驶系统和激光雷达2021-06-24
-
特斯拉涉嫌销售欺诈被判败诉,车主胜诉退一赔一!2021-06-24
-
在自动驾驶领域中,特斯拉为什么如此需要超级计算机?2021-06-23
-
特斯拉面临新威胁?亚马逊进军自动驾驶领域又一新动作2021-06-23
-
特斯拉换标意味着要发生品牌理念和价值的转变?2021-06-23
-
特斯拉在华销量起起伏伏,这背后究竟隐藏着什么?2021-06-22
-
红色背景换灰色背景,特斯拉换新Logo!2021-06-22
-
特斯拉如何用它的傲慢给中国新能源品牌新的机会?2021-06-22
-
特斯拉败了!终审被判向Model X车主“退一赔一”2021-06-21
-
5月份新能源销量:特斯拉回暖、秦PLUS看涨2021-06-21
-
视频版“特快攻略”来了 特斯拉推送“TESLA教程”视频演示2021-06-18
-
持续被特斯拉针对,为何小鹏被特斯拉如此重视?2021-06-18