医学影像AI为什么需要小数据学习?
医学影像AI为什么需要小数据学习?近年来,深度神经网络的出现一定程度上颠覆了医学影像行业的发展路径,人工智能介入下,影像相关科室繁杂重复的工作逐渐由算法接替,医生资源短缺这一问题似
近年来,深度神经网络的出现一定程度上颠覆了医学影像行业的发展路径,人工智能介入下,影像相关科室繁杂重复的工作逐渐由算法接替,医生资源短缺这一问题似乎出现了解决的希望。
但AI亦有其限制。从当前发展情况看,有效的人工智能算法大多聚集于存在大量标准化数据的病种,毕竟要实现高质量AI诊断,需要大量的高质量标注图像进行前期的算法训练。
这一数据相关的特质限制了医学AI的广泛应用。现实之中,罕见病和疑难杂症的数据较少,囿于患者隐私、数据安全等问题,数据收集行为的开展也较为困难。此外,医学图像的标注过程成本较高,对于不同的标注内容往往需要开发特殊的标注工具并交由有经验的医生进行。多方面原因协同下,某些医学图像问题的高标注质量医学图像数据集非常稀缺,其AI自然也难以孕育。
好在AI面临的困境并非没有解法。回想起来,人类只需通过极少的样本就能辨别新的事物,那么机器是否能以复制人类的这一能力呢?答案或许是可以的。最近医学AI领域兴起的一系列小数据学习方法便是以模仿人类的判别能力为目标,尝试通过减少需要的数据量,实现特定目标图像的识别,最终克服医学领域数据量少、标准缺乏的问题。
以先验知识为基础的小样本学习
要实现小样本学习(few-shot learning)必须要具备一些特定条件,譬如模型学习前已经吸收了一定类别的大量资料后,再加之新类别的极少量数据,最终实现小样本模型的形成。因此,小样本学习的关键是在算法中纳入合适的先验知识。
具体到医疗领域之中,很多医学图像模态中广泛存在器官的位置先验信息,例如CT图像中肝脏主要位于腹腔的右上位置,而脾则在腹腔的左上部分,这些位置先验信息对于AI识别特定类别的器官有非常大的帮助。
体素科技在顶级会议ISBI2021上发表的论文《Location Sensitive Local Prototype Network For Few-shot Medical Image Segmentation》便提出了一种基于位置先验信息的局部原型网络(location sensitive local prototype network,见图1)。该论文以肝和脾影像数据构建训练集,再将其收获先验信息的算法加入少量肾部影像分割任务,实现基于小样本学习的AI模型训练。
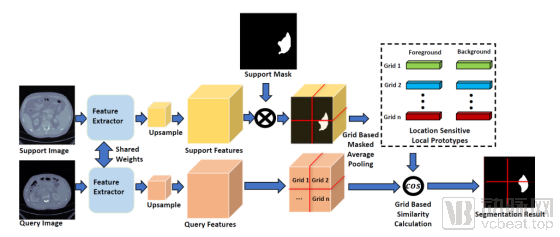
图一:基于位置先验信息的局部原型网络框架
在公开的CT器官分割数据集Visceral进行试验后,其结果表明,论文提出的新框架比目前的最好方法在Dice Score指标上提高了10%,显著推进了小样本下的器官分割这一领域的技术进展。
利用极端变化一致性来提高数据不足情况下医学图像分割的鲁棒性
除了数据获取困难这一问题外,研究人员在训练时还会遭遇数据来源不统一的问题。
由于医学图像的拍摄设备和拍摄环境和方式多样,各个医院和体检中心之间的人群分布差异明显,因此很难收集和标注足量的训练数据充分涵盖不同来源的图像特征。如果训练数据和实际测试数据存在明显的的分布差异(domain shift),生成的模型往往性能不佳。
体素科技在顶级会议MICCAI2020上发表的《Extreme Consistency: Overcoming Annotation Scarcity and Domain Shifts》为解决这一问题提供了方向。具体而言,该论文提出了极端一致性(extreme consistency)的概念,核心思想是在训练数据中加入极端的图像变换(比如大量强烈的亮度,对比度, 旋转, 尺寸变换),以增加训练数据的多样性,并假设这些极端的图像变换并不影响图像的语义含义。举例来说,眼底图像中的血管在经过极端的旋转和亮度对比度等变换后,依然能够对应血管本身。
为了实现这一构想,论文设计了一种半监督算法(semi-supervised learning, 见图2), 迫使模型遵守极端变化前和变化后的语义一致性这一约束,进而提高模型对于分布差异的鲁棒性。该论文在皮肤病变分割数据集(ISIC)和两个眼底血管分割数据集 (HRF和STARE)上进行了测试,展现了在数据不足和分布差异较大情况下,算法的鲁棒性和准确性的优势。
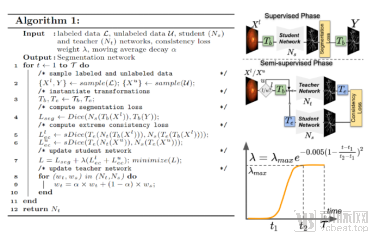
图2:左边是基于极端一致性的半监督学习方法的伪代码,右边是网络结构示意图。
少标注和弱标注情况下医学图像分割如何解决?
除了数据的来源问题,对已有数据进行分割标注同样需要研究人员付出大量成本。在中国,影像数据标注非常昂贵,尤其是像素级别的医学图像分割标注,人力支出更为巨大。因此,近期大量的研究工作试图解决不完善医学图像分割数据集中的两类典型问题:
· 标注稀缺。数据集中只有极稀少的图像数据有分割标注。
· 弱标签。数据集中的图像数据只有部分标注、或者标注带有噪声、或者只有图像级的类别标签没有逐像素的分割标注。
对于这两问题,体素科技发表在顶级期刊《Medical Image Analysis》中的文章《Embracing Imperfect Datasets: A Review of Deep Learning Solutions for Medical Image Segmentation》系统性地对现有方案进行了详细的回顾和分类总结(见图3所示)。根据医学图像分割数据集的不同缺陷,论文对这些方案的选择给出了实际的指导建议。

图3:医学分割图像数据集数据集缺陷问题及相应训练策略总结
近年来,体素科技和交大科研团队合作参与了多个医学AI挑战赛并获得佳绩。体素科技团队在ISBI2020学术会议上举办的ADAM比赛黄斑定位任务上获得了第三名的成绩。ADAM比赛是由百度灵医智慧和中山大学中山眼科中心联合举办,包含了黄斑定位等四个任务,吸引了来自20多个国家的近400支参赛队伍。

黄斑区域是眼底的一个特别重要的功能区域,精确定位黄斑对于进一步的辅助诊断很有帮助。该任务一大难点是,很多严重影响视力的眼底疾病都发生在黄斑区域,使其外观和正常黄斑相比有较大变化,导致现有常见深度学习模型对于病变黄斑的定位不够鲁棒。体素科技团队创新性的设计了一个双流网络融合眼底图像和对应的血管分割信息,可以借助于眼底血管形状和走向信息来估计黄斑的位置,大大提高了严重病变的黄斑区域定位效果。该模型在ADAM比赛决赛中平均黄斑定位误差为25个像素(排名第3), 体现了一定的临床可用性。
除此之外,体素科技团队在COVID-19 Lung CT Lesion Segmentation Challenge - 2020(“肺部CT新冠肺炎分割2020”国际挑战赛)中获佳绩,在肺炎分割关键指标Dice Score上排名第2,所有指标加权排名第3。

COVID-19-20国际挑战赛是由Children‘s National Hospital联合英伟达(NVIDIA)、美国国立卫生研究院(NIH)和国际医学图像计算和计算机辅助干预协会(MICCAI)举办的国际竞赛,设置了分割和量化由SARS-CoV-2感染引起的肺部病变(主要是毛玻璃影)的挑战任务,旨在探究基于深度学习的肺炎病灶分割模型用于COVID-19 CT 影像定量分析的可行性,为COVID-19 鉴别诊断提供帮助。COVID-19-20国际挑战赛吸引了来自29个国家的200多支参赛队伍。
此次获奖的新冠肺炎分割模型采用目前在各类医学图像分割任务中均表现突出的深度学习模型nn-Unet 框架进行肺炎病灶分割,对图像分割中的各个环节,包括图像预处理,网络架构和学习过程等都进行了自动化的优化和参数估计。同时为了解决噪声标注带来的模型优化方向偏离以及在医学影像中普遍存在的前景背景类别不平衡的问题,体素科技团队选取了Noise-Robust Dice Loss作为模型的优化损失。最终该模型在同源测试集上Dice Score为0.6581(排名第2)。
作者:动脉网
-
国家统计局发布工业生产数据,汽车制造业营收81557亿2021-01-28
-
自助分析平台,助力开启数据化运营之路2021-01-27
-
以数据驱动新商业价值,国内中小型企业如何运用NAS进行数据运营2021-01-27
-
最新数据!印度首都超一半人感染过新冠!2021-01-26
-
国内主流市场细分车型保值率数据解析2021-01-22
-
做政企客户的“首席数据官”,UCloud助力政企数字化 “升档提速”2021-01-20
-
烽火智慧高速:数据赋能天府机场高速公路智慧化建设2021-01-20
-
OPPO小布助手算法能力问鼎百度"千言数据集:文本相似度"行业测评2021-01-19
-
一文读尽:数据趋势、数据治理、数据架构、数据中台、云数据库、数据安全2021-01-19
-
求解大数据时代在线教育的长期价值2021-01-18
-
谷歌收购Fitbit引发用户隐私担忧:数据将独立保存2021-01-18
-
3D打印镜片具有不同折射率,未来数据传输的首选?2021-01-18
-
IFI Claims数据显示,3D打印成为2020年增长最快的十大技术之一2021-01-18
-
大数据分析会遇到怎样的难题?2021-01-13
-
工业大数据在制造企业的应用有哪些?2021-01-13