Python数据科学:决策树
Python数据科学:决策树决策树呈树形结构,是一种基本的回归和分类方法。决策树模型的优点在于可读性强、分类速度快。下面通过从「译学馆」搬运的两个视频,来简单了解下决策树。最后来实
决策树呈树形结构,是一种基本的回归和分类方法。
决策树模型的优点在于可读性强、分类速度快。
下面通过从「译学馆」搬运的两个视频,来简单了解下决策树。
最后来实战一波,建立一个简单的决策树模型。
/ 01 / 决策树算法
本次主要涉及两类决策树,Quinlan系列决策树和CART决策树。
前者涉及的算法包括ID3算法、C4.5算法及C5.0算法,后者则是CART算法。
前者一系列算法的步骤总体可以概括为建树和剪树。
在建树步骤中,首先选择最有解释力度的变量,接着对每个变量选择最优的分割点进行剪树。
剪树,去掉决策树中噪音或异常数据,在损失一定预测精度的情况下,能够控制决策树的复杂度,提高其泛化能力。
在剪树步骤中,分为前剪枝和后剪枝。
前剪枝用于控制树的生成规模,常用方法有控制决策树最大深度、控制树中父结点和子结点的最少样本量或比例。
后剪枝用于删除没有意义的分组,常用方法有计算结点中目标变量预测精度或误差、综合考虑误差与复杂度进行剪树。
此外在ID3算法中,使用信息增益挑选最有解释力度的变量。
其中信息增益为信息熵减去条件熵得到,增益越大,则变量的影响越大。
C4.5算法则是使用信息增益率作为变量筛选的指标。
CART算法可用于分类或数值预测,使用基尼系数(gini)作为选择最优分割变量的指标。
/ 02/ Python实现
惯例,继续使用书中提供的数据。
一份汽车违约贷款数据集。
读取数据,并对数据进行清洗处理。
import os
import pydotplus
import numpy as np
import pandas as pd
import sklearn.tree as tree
import matplotlib.pyplot as plt
from IPython.display import Image
import sklearn.metrics as metrics
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split, ParameterGrid, GridSearchCV
# 消除pandas输出省略号情况
pd.set_option('display.max_columns', None)
# 设置显示宽度为1000,这样就不会在IDE中换行了
pd.set_option('display.width', 1000)
# 读取数据,skipinitialspace:忽略分隔符后的空白
accepts = pd.read_csv('accepts.csv', skipinitialspace=True)
# dropna:对缺失的数据进行删除
accepts = accepts.dropna(axis=0, how='any')
# 因变量,是否违约
target = accepts['bad_ind']
# 自变量
data = accepts.ix[:, 'bankruptcy_ind':'used_ind']
# 业务处理,loan_amt:贷款金额,tot_income:月均收入
data['lti_temp'] = data['loan_amt'] / data['tot_income']
data['lti_temp'] = data['lti_temp'].map(lambda x: 10 if x >= 10 else x)
# 删除贷款金额列
del data['loan_amt']
# 替换曾经破产标识列
data['bankruptcy_ind'] = data['bankruptcy_ind'].replace({'N': 0, 'Y': 1})
接下来使用scikit-learn将数据集划分为训练集和测试集。
# 使用scikit-learn将数据集划分为训练集和测试集
train_data, test_data, train_target, test_target = train_test_split(data, target, test_size=0.2, train_size=0.8, random_state=1234)
初始化一个决策树模型,使用训练集进行训练。
采用基尼系数作为树的生长依据,树的最大深度为3,每一类标签的权重一样。
# 初始化一个决策树模型
clf = DecisionTreeClassifier(criterion='gini', max_depth=3, class_weight=None, random_state=1234)
# 输出决策树模型信息
print(clf.fit(train_data, train_target))
输出的模型信息如下。

对生成的决策树模型进行评估。
# 输出决策树模型的决策类评估指标
print(metrics.classification_report(test_target, clf.predict(test_data)))
# 对不同的因变量进行权重设置
clf.set_params(**{'class_weight': {0: 1, 1: 3}})
clf.fit(train_data, train_target)
# 输出决策树模型的决策类评估指标
print(metrics.classification_report(test_target, clf.predict(test_data)))
# 输出决策树模型的变量重要性排序
print(list(zip(data.columns, clf.feature_importances_)))
输出如下。
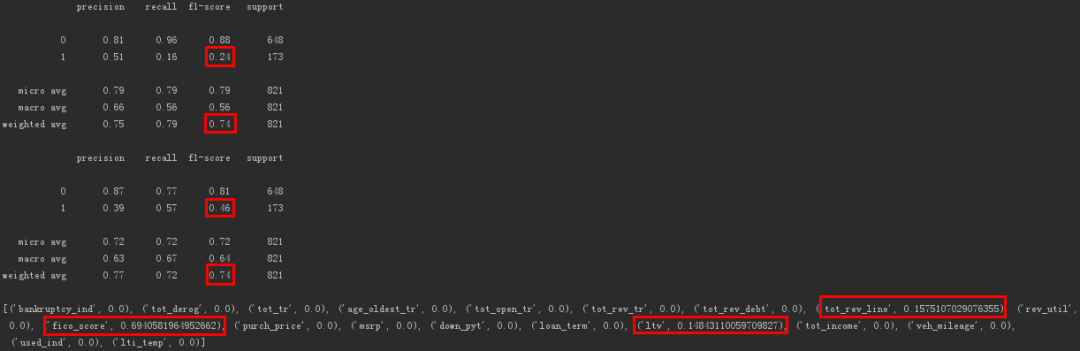
可以看出对因变量标签进行权重设置后,模型对违约用户的f1-score(精确率和召回率的调和平均数)提高了,为0.46。
违约用户被识别的灵敏度也从0.24提高到了0.46。
此外决策树模型的变量重要性排序为「FICO打分」、「信用卡授权额度」、「贷款金额/建议售价*100」。
首页 下一页 上一页 尾页上一篇:python修炼day32!
-
python修炼day32!2019-05-28
-
使用Python+OpenCV进行图像处理(三)2019-05-28
-
python学习笔记——pip的安装和使用2019-05-28
-
联通大数据携手云粒智慧助力智慧政务转型升级2019-05-28
-
AI+产业大数据助力区域创新体系建设2019-05-28
-
大数据面试真题,来试试你有几斤几两2019-05-28
-
50行代码能做什么?教你用50行python代码制作一个计算器2019-05-28
-
Python数据科学:神经网络2019-05-28
-
SparkMLlib GBDT算法工业大数据实战2019-05-28
-
泛在电力物联网下大数据发展与应用2019-05-28
-
大数据助智能汽车跑上大马路2019-05-28
-
企业如何实现对工业大数据的预处理?2019-05-28
-
5个用python编写非阻塞web爬虫的方法2019-05-28
-
初识MapReduce的应用场景(附JAVA和Python代码)2019-05-28
-
径卫视觉:发挥AI大数据平台优势,用科学管理守护道路交通安全2019-05-28