清华大学研究团队获KDD 2020首届时间检验应用科学奖
清华大学研究团队获KDD 2020首届时间检验应用科学奖ACM SIGKDD(ACM SIGKDD Conference on Knowledge Discovery and Da
ACM SIGKDD(ACM SIGKDD Conference on Knowledge Discovery and Data Mining,国际数据挖掘与知识发现大会,简称 KDD)是数据挖掘领域国际顶级学术会议,今年的 KDD 大会将于 8 月 23 日至 27 日在线上召开。
8 月 13 日, SIGKDD 2020 官方公布了 2020 年 ACM SIGKDD 创新奖、服务奖、论文奖、新星奖、时间检验研究奖、时间检验应用科学奖等六项大奖的获得者,这些奖项是针对数据科学、机器学习、大数据和计算机科学领域的杰出个人和研究团队而设立的。
值得一提的是,今年 KDD 颁发了首届时间检验应用科学奖(Test of Time Award for Applied Science)奖项,以表彰在数据科学的实际应用中具有影响力的研究。清华大学计算机科学与技术系唐杰、李涓子等人凭借他们在 2008 年发表的关于学术社交网络挖掘的研究成果获得了这一奖项。
获奖论文题目为 ArnetMiner: Extraction And Mining Of Academic Social Networks,论文作者包括清华大学计算机科学与技术系的唐杰、张静、姚利敏、李涓子,以及来自 IBM 中国研究实验室的张莉和苏中。

在这篇文章中,作者主要介绍了一个自主研发的面向研究者社会网络的挖掘搜索系统 ArnetMiner 的体系结构和关键技术。下面我们来将详细解读一下这篇文章。
研究背景
近些年,学术社交网络发展迅速,为众多研究学者提供了良好的交流平台,也产生了巨大的学术信息数据集。随着数据挖掘和人工智能技术的发展,针对学术社交网络进行数据挖掘和知识提取,进而为科学研究领域提供全方位的服务成为一大研究热点。
在作者开始这项研究之时,学术圈已有 DBLP、CiteSeer、Google Scholar 等学术搜索系统发布,但是往往存在以下两项不足之处:
1)缺乏语义信息。无论用户输入的个人资料或使用启发式方法提取的各类信息,语义存在不完整或不一致性,缺少有效获得大规模语义信息的方法;
2)缺乏异构对象的统一建模方法。以前,学术网络中不同类型的信息如学者、论文、会议期刊是单独建模的,因此无法准确捕捉它们之间的依赖关系。
为解决这两个问题,作者所在的研究团队开发了ArnetMiner系统。该系统旨在解决以下几个问题:
1)如何自动从互联网海量信息中提取研究人员的个人档案?
2)如何集成不同来源提取的学术相关信息(例如研究人员的个人档案和出版物)?
3)如何以统一的方法为不同类型的信息建模?
4)如何基于已构建的网络,提供强大的挖掘和搜索服务?
ArnetMiner系统(简称AMiner)
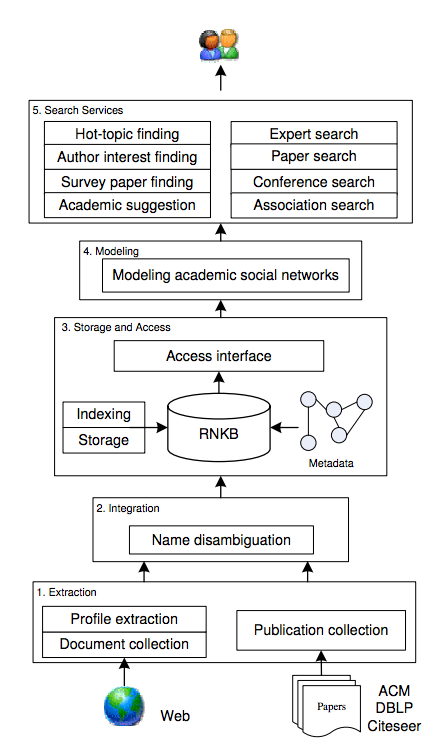
图1:AMiner系统框架图
图 1 给出了 AMiner 系统框架图,AMiner 系统自下而上主要包括五个部分:
1)研究者个人信息抽取(Extraction):即从网络上自动识别到研究者的个人主页,并训练一个统一的模型,从中抽取研究者的各种基本信息。同时,从不同来源的论文数据库抽取或收集作者所发表的论文信息;
2)个人信息融合(Integration):通过使用研究者姓名作为标识符,将提取的研究者的个人资料和提取的出版物信息进行整合。提出了马尔科夫随机场概率模型,以解决融合不同来源论文数据时面临的重名歧义问题;
3)存储和访问(Storage and Access):系统将集成的数据存储在研究者网络知识库(RNKB)中,利用MySQL作为存储数据库,并使用反向文件索引方法进行信息索引;
4)建模(Modeling):文章提出一个概率生成模型,通过对学术网络中的研究者、论文、会议等不同类型的信息进行综合分析,对每种信息进行主题分布估计;
5)搜索服务(Search Services):基于建模结果,提供多种搜索服务,包括专家搜索、关联关系搜索、论文推荐以及引用推荐等。
该系统重点解决三个技术难点:
1)学术网络中研究者个人信息自动抽取问题;
2)不同来源学术论文融合过程中的重名排歧问题;
3)学术网络中研究者、论文、会议等异质实体的统一建模问题。
3 首页 下一页 上一页 尾页-
目标检测:ECCV 2020附代码论文合集2020-08-23
-
重磅 《柳叶刀》发表陈薇院士论文:中国新冠病毒疫苗安全有效2020-05-23
-
北大计算机学霸 百度李彦宏发表医学论文:关注癌症2020-05-16
-
芯翼信息科技参与的技术成果论文入选ISSCC 20202020-04-15
-
给力!湖南大学研制出防疫机器人 协助医务工作者共同抗疫2020-03-27
-
新冠病毒已突变!论文作者:“侵略性”用词有误导2020-03-14
-
AAAI入选论文再创新高,百度提振中国AI信心2020-02-18
-
AAAI 2020:我国论文录取数量盘踞榜首,清华夺得最佳学生论文2020-02-11
-
AAAI 2020 开幕:百度28篇论文入选 涉及NLP、机器学习、视觉等领域2020-02-11
-
揭秘Siri,苹果发布论文阐释语音助手设计想法2020-02-06
-
玛塔创想携新品亮相CES,助力儿童成为科技创作者2020-01-10
-
11篇论文亮相人工智能顶会,阿里认知智能领域研究全球领先2019-12-12
-
联发科技ISCC论文量位居半导体行业前三 聚焦5G、AI和AIoT2019-11-25
-
腾讯优图实验室13篇论文入选ICCV20192019-10-25
-
《Nature》登出谷歌“量子霸权”论文 评价其为里程碑式成就2019-10-24